AlexNet
This article contains a brief explanation of the paper ImageNet Classification with Deep Convolutional Neural Networks by Alex Krizhevsky et.al . The paper discusses how the depth of the network can give improved results on datasets when implemented through GPUs.
The article has been subdivided into following sections:
- History
- Problem Statement
- Network Architecture
- Features of AlexNet
- Regularisation Techniques
- Conclusion
- References
History
“AlexNet” is a Convolutional Neural network architecture named after the author Alex Krizhevsky. The network is trained on the ImageNet LSVRC 2010 dataset consisting of 1.2 million high resolution images of 1000 different classes. The variant of the network won the ILSVRC 2012 contest with the top-5 error rate of 15.3% compared to runner up error rate of 26.2%. The network is a variant of the classic Lenet-5 architecture by Yann LeCun et.al with deeper layers and modern regularisation techniques.
Problem Statement
The limitations of deep learning is it requires more data to give better results. For large datasets there is a need to use models with a large learning capacity with higher complexity. To handle these problems, a variant of CNN is proposed with more depths i.e layers and suitable hyperparameters that can efficiently learn from the dataset and has fewer connections compared to the standard feedforward layers. Besides, with larger models the computational power requirement is more, hence it becomes expensive to train. When GPUs are paired with highly optimised implementation of convolution, they become powerful enough to train a larger network.
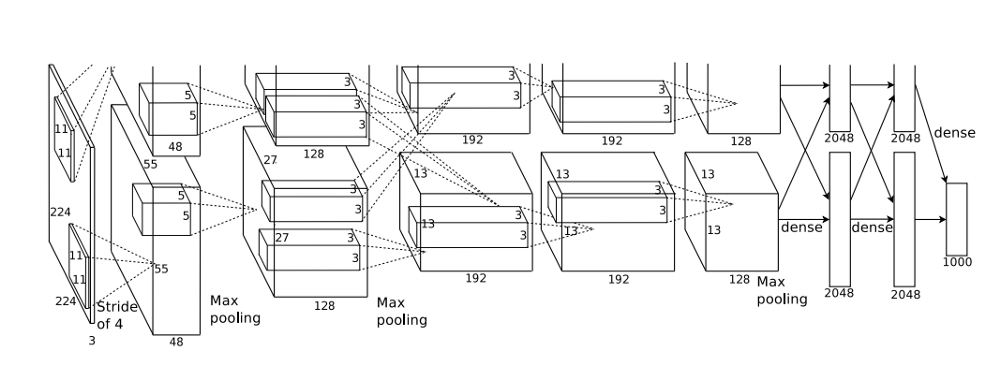
Network Architecture
Alexnet is a convolutional network trained on Imagenet dataset with 1.2 million images with over 1000 classes. The architecture is made up of 8 learned layers, consisting 5 convolutional layers and 3 fully connected layers combined with max-pooling, activation function and various regularisation techniques.
The paper specifies that the image size is 224 x 224 x 3, but as per Andrej Karapathy it must be 227 x 227 x 3 for correct mathematical computation.
The output of the last fully connected layers is fed into a 1000-way softmax function, to get the desired distribution over the 1000 labels.

Features of AlexNet
The features that makes alexnet special in implementing larger datasets are as follows:-
- ReLU Activation Function
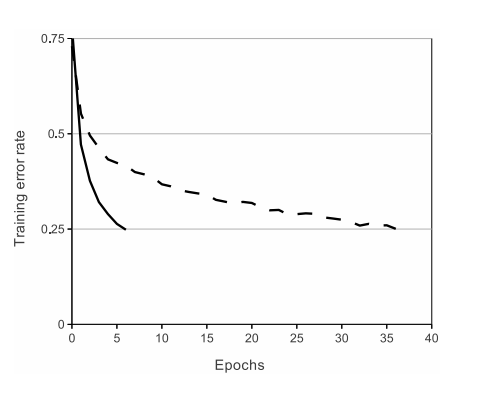
Neural architecture utilises activation functions to introduce non-linearity in the network so that the model can be trained to learn complex relationships among the parameters. Traditional networks used tanh(x) or sigmoid as activation functions. This suffered through the problem of vanishing gradient. AlexNet used ReLU as an activation function which has less training time than the standard method. ReLU showed a 6x faster training time on CIFAR-10 dataset for achieving 25% error rate than the tanh(x) function.
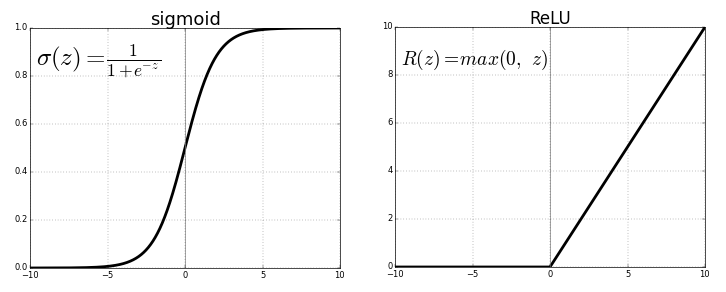
- Utilisation of GPUs
AlexNet is trained on GTX 580 GPUs having just 3GB of memory. The insufficient memory caused the network to be trained on 2 GPUs as it was too large to fit in a single GPU. The filters are distributed in half among the two GPUs, with communication allowed between only the selected layers. This connection orientation depends on the model, but the method took less computation time than a single GPU due to resource sharing.
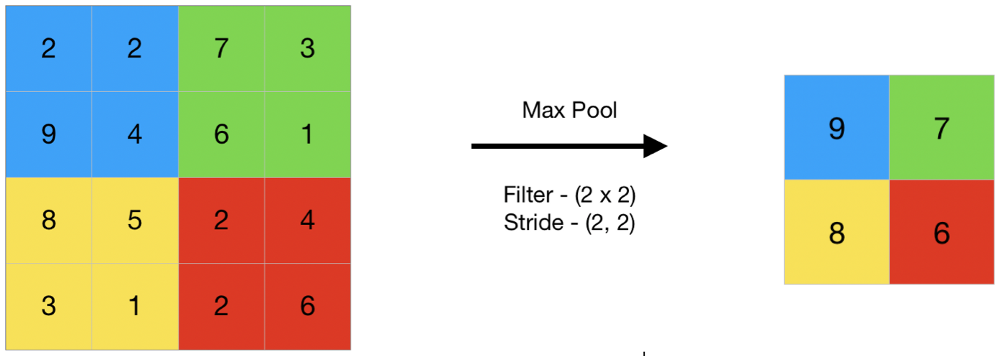
- Overlapping Pooling
AlexNet utilises Pooling layers, which is used to reduce the dimension of feature map and summarise the feature present in the region of the feature map. Pooling helped reduce the computation time and complexity. The scheme helped achieve the top 1 and top 5 error rates by 0.4% and 0.3% respectively.
Regularisation Techniques
With over 60 million parameters and 1000 labels, the alexnet suffers from the problem of overfitting. The method used to overcome overfitting are:
- Data Augmentation
It is a method of doing transformation in the original data to produce new data points. We do minor changes in the existing dataset helping us to amplify the dataset, giving the model more ground to explore and train on.
The data augmentation forms in AlexNet are image translation, horizontal reflection and random cropping. This increases the training set by a factor of 2048. It also performed Principal Component Analysis (PCA), altering the intensities of the RGB channels in the training images. It reduced the top 1 error rate by > 1%.
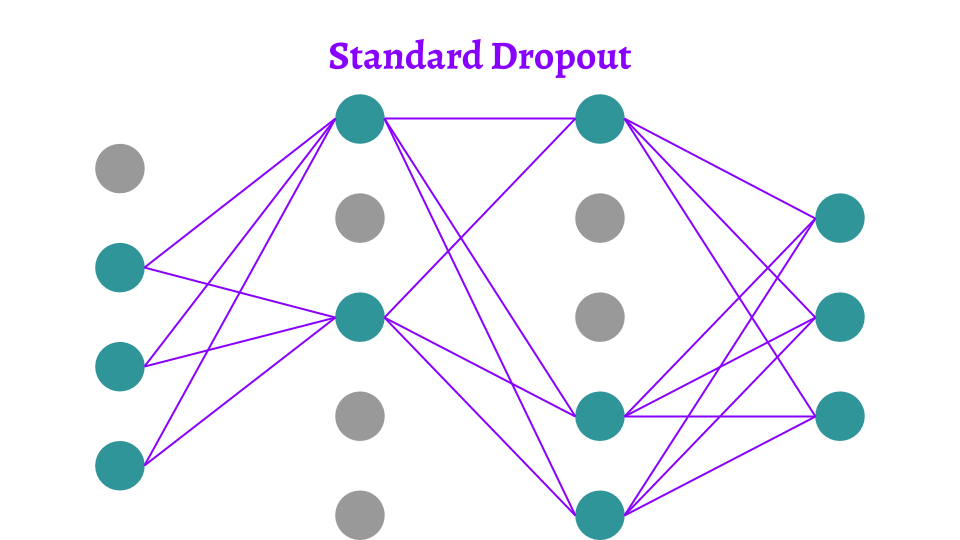
- Dropout
It is a method which temporarily removes units, forward and backward connections from the parent, giving rise to a new network. The training is performed on multiple networks based on the number of iterations, hence giving the model a wider ground to experiment and improve.
AlexNet used the concept of Dropout with rate at 0.5, i.e randomly dropping half the total number of neurons in each epoch. Without dropout the network exhibited substantial overfitting.
Conclusion
AlexNet produced a top-5 error rate of 18.2% in the ILSVRC 2012 contest. Upon averaging the predictions of 5 similar CNNs it gave an error rate of 16.4%.
AlexNet proved to be a major upgrade after the classic networks like Lenet-5, and is considered a milestone of CNN for image classification. Many techniques such as pooling, dropout, GPUs, ReLU are still practised in the designing of newer models. The use of normal distribution for weight initiation was not effective in solving vanishing gradient problem, hence replaced by Xavier Method later.
After AlexNet, several newer models were invented such as VGGNet, GoogleNet and ResNet which are deeper than AlexNet. ResNet (3.6%) and GoogleNet (6.7%) surpassed AlexNet in efficiency.